基于工作量证明(PoW)的验证码系统的简单实现
前言
CAPTCHA全称Completely Automated Public Turing test to tell Computers and Humans Apart,译为全自动区分计算机和人类的图灵测试,是指各种认证方法,这些方法利用一个对于人类来说很简单但对机器来说很难的挑战来测试用户,以验证用户是否为人类。
随着人工智能技术不断发展,许多传统的验证码测试系统被计算机轻易通过,因此许多厂商不断推出各种创新性的方法,然而大多数情况下机器根据一些标注数据进行训练后,也能够快速适应新的这些系统,反倒是对于用户而言,要花时间学习新的验证方式,徒增客户烦恼。
现在的一些验证码过于奇葩,例如:
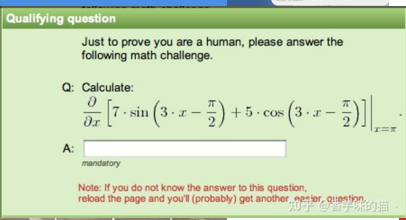

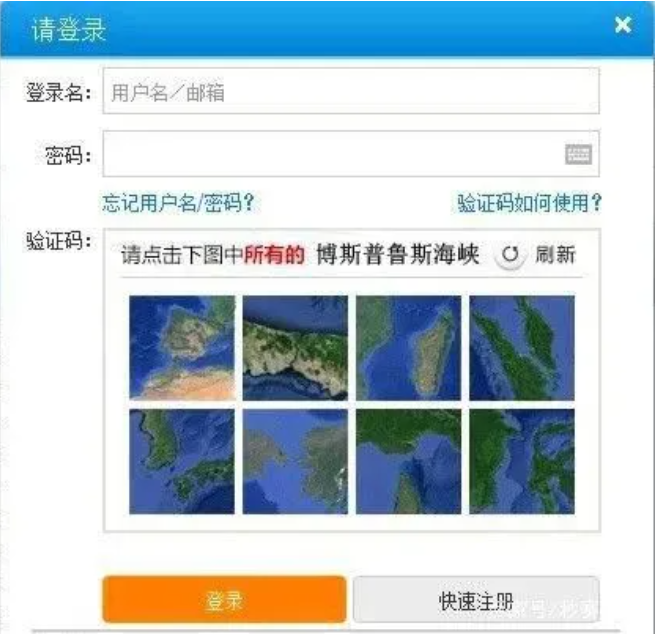
在我看来,现在的验证码系统多多少少有些本末倒置了,把人类难住了,计算机却放过了。
因此有必要对现有的验证码系统做出改进。
工作量证明POW
原理
工作量证明即在获取我的服务之前,你需要向我证明你做了一定量的工作。
很常用的一种方法是通过寻找哈希值的方式,即你花费算力,寻找某些特定条件的哈希值,由于哈希函数的不可逆性和不可预测性,你不得不通过迭代的方式进行寻找,但是对于我而言,验证过程是很容易的,只需要将你给的值计算一遍哈希值,检查哈希值是否符合条件,只要符合条件,就说明你的确做了一定量的工作。
为了防止你使用彩虹表的方式记录下指定字符串的哈希值,我要给一个随机字符串prefix,你再在这基础之上寻找一个后缀,使得两者拼接后的哈希值符合条件。
以上就是一个简单的基于pow的验证码系统的大致原理了,下面是实现过程
好吧,我承认这篇文章的确有些标题党了,这个方式并不是真正意义上的captcha,因为它并没有往区分人类与机器人的功能上走,但是今天的验证码系统的目的是什么?绝大多数是为了防止机器人访问吧,例如在登录页面放入验证码系统,防止机器人通过口令爆破的方式获取指定用户的密码,即先判断是人类,再判断输入的密码,因为人类输入内容速度较慢,以人工的方式爆破密码不现实。
而基于pow的系统,我并不关心访问者是人类还是机器,因为在验证你提交的密码之前,我先验证你的工作量,也可以说是“浪费”你的算力,对于人类而言,反正这个工作是计算机进行,用户无需干预,只需等一小会即可,反观机器人,为了爆破密码,每次提交不同的密码之前,都要花费一定时间解决pow难题,这么算下来,爆破速度和人类手工爆破速度一致,为了获取真实密码,花费的时间成本太大,那还不如不爆破了。
什么,你说美国人想用混合精度高达每秒1,000,000,000,000,000,000次的目前超算能力排名第一的超计算机Frontier来爆破我的博客系统管理员密码?
从这个意义上来说,基于pow的也算得上是一个称职的验证码系统,因为的确达到了减缓机器人爆破的目的,只不过这个验证码是一个哈希值,是由计算机去计算的,无需用户干预,提升了用户体验。
实现
为了实现这个过程,需要客户端和服务端共同努力,整个流程如下图:
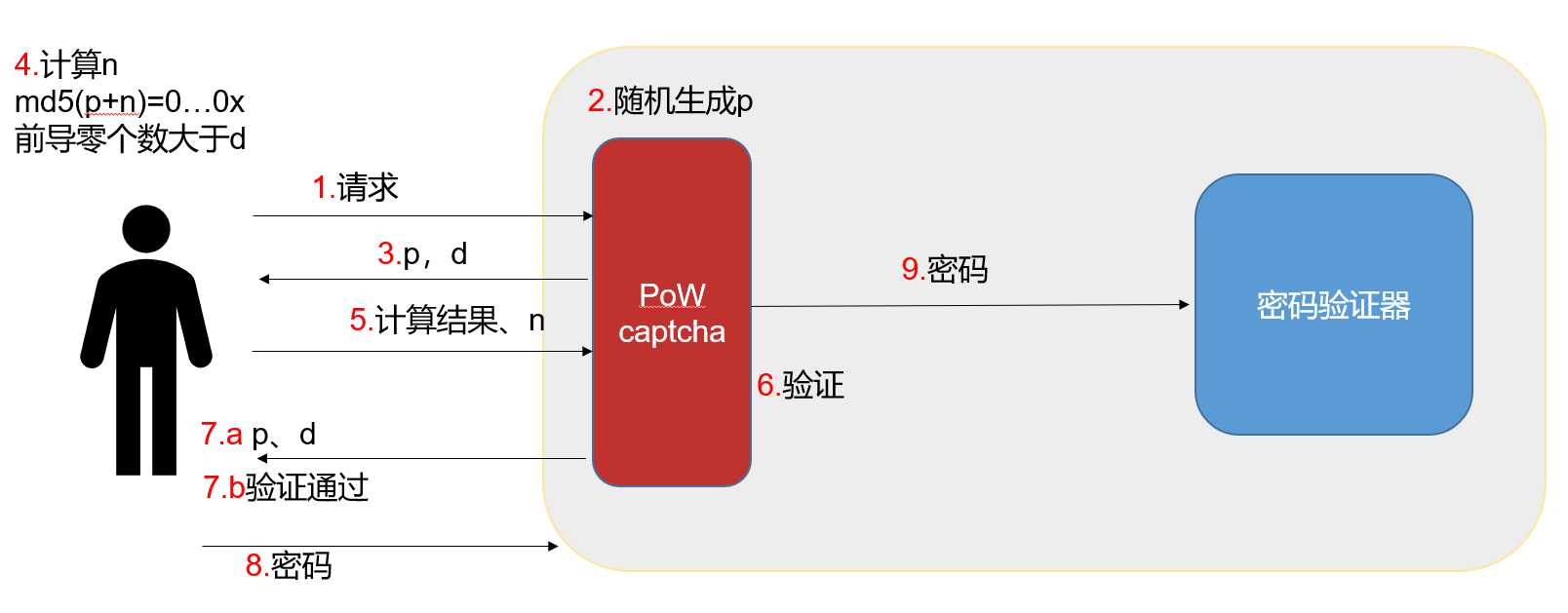
首先客户端要请求服务端,服务端随机生成前缀字符串prefix,将该字符串连同困难度difficult返回给客户端,客户端以迭代方式计算后缀,使得前后缀的哈希值符合条件,然后将后缀以及对应的哈希值提交给服务端,服务端再结合之前生成的前缀,验证这个后缀是否符合条件,一方面,如果符合条件,在session中标记,然后通知客户端可以提交密码,收到用户提交的密码时候,第一件事就是判断session中有无标记,避免用户不进行pow而直接提交密码;另一方面,如果验证不通过,则重新生成一个随机前缀,重复上述步骤.
实现效果:

安装与使用
安装
npm i @yalexin/pow-captcha
基础用法
const Captcha = require("@yalexin/pow-captcha");
// api1 接口用于产生一个随机前缀和困难度
// api2 接口用于验证客户端的数据是否正确
const [api1, api2] = ['http://server.com/powConfig', 'http://server.com/powVerify'];
Captcha.startPoW(api1, api2).then(res => {
console.log(res);
}).catch(e => {
console.log(e);
}
)
高级用法
// 高级用法中,需要我们传递一个axios对象(实际上传递一个支持调用get和post方法的任意对象即可)
// 这种情况一般用于我们自己封装axios,例如我们可能会做一些拦截器、跨域代理功能
const Captcha = require("@yalexin/pow-captcha");
// api1, api2 解释同上
const [api1, api2] = ['http://server.com/powConfig', 'http://server.com/powVerify'];
Captcha.getPoWWithAxios(api1, this.$axios).then(config => {
Captcha.tryPoWWithAxios(api2, config, this.$axios).then(verifyResult => {
console.log('verifyResult = ', verifyResult);
}).catch(e => {
console.log(e);
})
}).catch(e => {
console.log(e);
}
)
API
服务端(需要自己实现,可参考下面的)
服务端必须实现两个接口:CONFIG_URL和VERIFY_URL
随机前缀接口
在CONFIG_URL接口中,需要返回一个json数据,格式如下:
{
"difficulty":5,
"prefix":"Ve03Plle"
}
例如,对于Java,实现代码如下:
// @Controller
@GetMapping("/powConfig")
public ResponseEntity getPowConfig(HttpServletRequest request,
HttpServletResponse response) {
Map map = userService.getPowConfig(request, response);
return new ResponseEntity(map, HttpStatus.OK);
}
// @Service
@Override
public Map getPowConfig(HttpServletRequest request, HttpServletResponse response) {
String randomString = getRandomString(powPrefixLength);
HashMap<Object, Object> hashMap = new HashMap<>();
hashMap.put("prefix", randomString);
hashMap.put("difficulty", powDifficulty);
request.getSession().setAttribute("powConfig", hashMap);
return hashMap;
}
private String getRandomString(int length) {
String str = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789";
Random random = new Random();
StringBuffer sb = new StringBuffer();
for (int i = 0; i < length; i++) {
int number = random.nextInt(62);
sb.append(str.charAt(number));
}
return sb.toString();
}
验证接口
在VERIFY_URL接口中,需要接收一个json数据(该数据由客户端以post方式提交),格式如下:
{
"data":{
"md5Str":"00000119414c7a8c9678b96fbc4954be",
"paddingNum":300880
}
}
paddingNum即用户暴力迭代寻找到的后缀.
服务端要在这个接口中完成两个验证:
md5Str==md5(prefix+paddingNum)md5Str前导零个数至少是difficulty
difficulty 和 prefix 对应于在接口CONFIG_URL中返回的内容.
例如,对于Java,实现代码如下:
// @Controller
@GetMapping("/powConfig")
public ResponseEntity getPowConfig(HttpServletRequest request,
HttpServletResponse response) {
Map map = userService.getPowConfig(request, response);
return new ResponseEntity(map, HttpStatus.OK);
}
// @Service
@Override
public Map getPowConfig(HttpServletRequest request, HttpServletResponse response) {
String randomString = getRandomString(powPrefixLength);
HashMap<Object, Object> hashMap = new HashMap<>();
hashMap.put("prefix", randomString);
hashMap.put("difficulty", powDifficulty);
request.getSession().setAttribute("powConfig", hashMap);
return hashMap;
}
private String getRandomString(int length) {
String str = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789";
Random random = new Random();
StringBuffer sb = new StringBuffer();
for (int i = 0; i < length; i++) {
int number = random.nextInt(62);
sb.append(str.charAt(number));
}
return sb.toString();
}
客户端
Captcha.startPoW()和Captcha.tryPoWWithAxios()会返回一个promise对象,如果通过验证,则会在then中返回一个对象resobj,该对象内容如下:
{
verify: true,
tryServerCnt: tryServerCnt,
totalTryCnt: totalTryCnt
}
| 字段 | 描述 |
|---|---|
| verify | 服务端验证结果 |
| totalTryCnt | 总迭代次数 |
开发历程
- 2023-06-19 完成第一版代码设计,使用
webpack打包后,即可使用。 - 2024-05-19完成第二版代码设计,以
npm包形式打包发布
目前客户端代码存放于GitHub


本文由「黄阿信」创作,创作不易,请多支持。
如果您觉得本文写得不错,那就点一下「赞赏」请我喝杯咖啡~
商业转载请联系作者获得授权,非商业转载请附上原文出处及本链接。
关注公众号,获取最新动态!